Yes, a familiar situation. You have a sound framework on paper but resilience is not embedded in how the organisation runs day to day.
1. Key weaknesses in current arrangements

Illustration: today, if a major outage occurred, you would probably depend heavily on a few key individuals and ad hoc coordination rather than confidently lifting a set of tested, role‑based playbooks off the shelf.
2. Where plans, and accountability are unclear
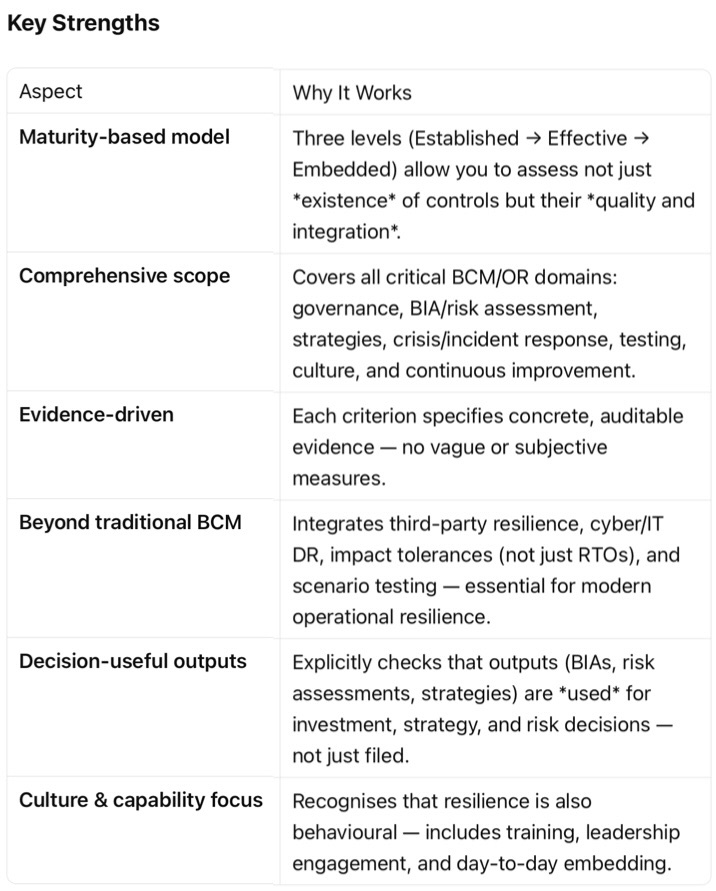
- Governance: policy and committee structures exist, but OR is not yet fully integrated into enterprise risk, strategy, change, and assurance processes. This makes accountability blurry at executive level (who “owns” resilience outcomes versus activities).
- Critical services/BIA/risk: methodologies and outputs are defined, but they are not maintained as a “living” source of truth or consistently used across disciplines (IT DR, cyber, vendor management, etc.).
- Strategies & solutions: there is a defined approach and documented strategies, but alignment with risk appetite, budgets, change programs and other resilience initiatives is weak, so decisions during projects and investments may not consider resilience sufficiently.
- Roles & capability: there is no clear, organisation‑wide view of OR roles, competencies, and training/awareness expectations (e.g. crisis leaders, service owners, vendor resilience leads). People may not know what is expected of them in a disruption.
- Performance & continuous improvement: there is no agreed set of resilience metrics, review cadence, or link into issues/corrective action processes, so no one is clearly accountable for closing gaps and demonstrating improvement over time.
In practice, this means resilience is still seen more as a set of documents and projects than as a managed performance area with clear owners, measures, and consequences.

3. Practical priorities (what to fix first)
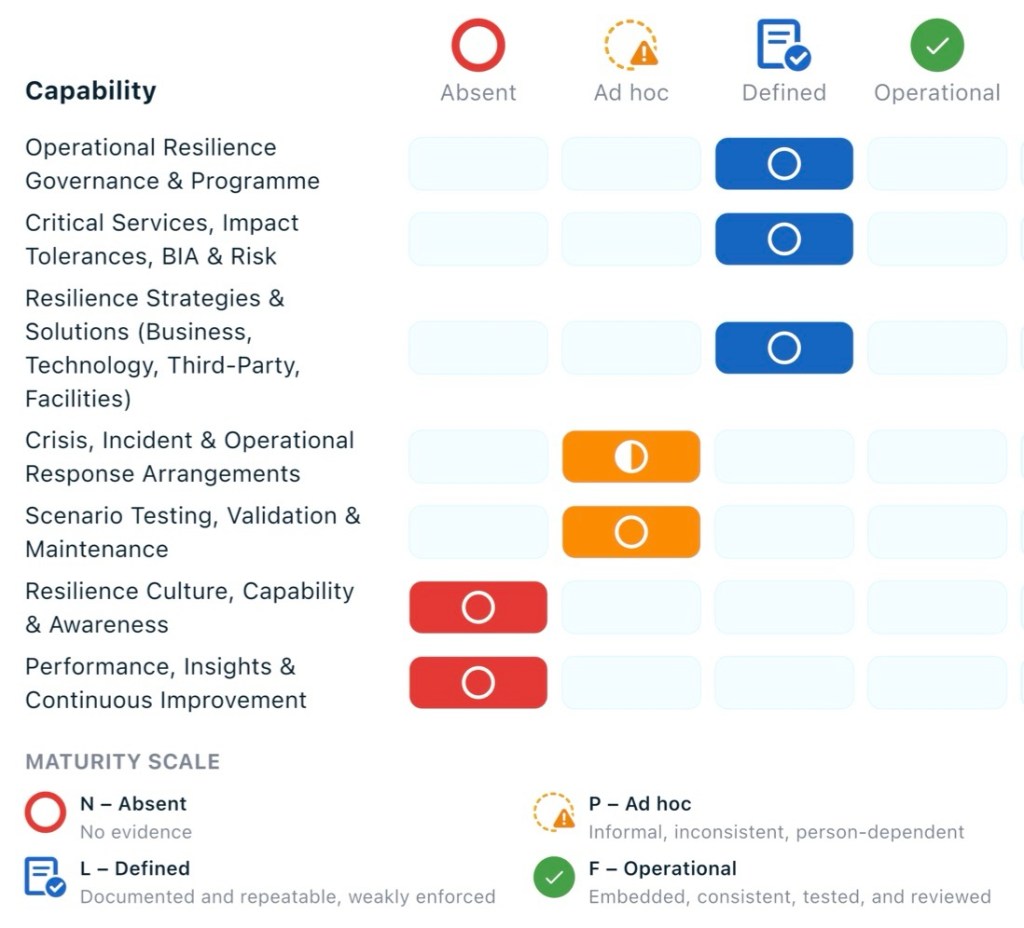
Focus first on the areas rated N (Absent) and P (Ad hoc), then strengthen linkages in the L (Defined) domains.
1. Establish performance and oversight basics
(Performance, Insights & Continuous Improvement – N).
- Define a small, meaningful set of OR metrics/KRIs (e.g. critical service coverage, currency of BIAs and plans, test pass rates, incidents vs impact tolerances).
- Set a quarterly OR performance review rhythm into an existing executive or risk committee, with clear ownership for actions and tracking.
2. Build roles, skills, and awareness
(Resilience Culture, Capability & Awareness – N).
- Clarify key OR roles and responsibilities (service owners, crisis managers, BC coordinators, IT DR leads, vendor resilience owners) and map them to people.
- Create a simple training and awareness plan: short role‑based briefings for key roles, basic OR awareness for all staff, and targeted crisis/incident leadership training.
3. Make scenario testing and learning real
(Scenario Testing, Validation & Maintenance – P).
- Use the existing testing framework to run a small number of high‑value, cross‑functional exercises focused on top critical services and impact tolerances.
- Implement a central lessons‑learned log with owners and due dates, linked to change, risk, and improvement processes so fixes are actually delivered.
4. Strengthen the usability of response arrangements
(Crisis, Incident & Operational Response – P).
- Prioritize 3–5 key crisis and incident playbooks and BC/DR plans for simplification into short, role‑based, action‑oriented guides.
- Confirm how plans are accessed in a crisis (including offline) and test this in exercises to make sure people can find and use them quickly.
5. Keep critical services, BIAs and strategies “alive”
(Governance, Critical Services, Strategies – L).
- Stand up a single source of truth for critical services, impact tolerances, BIAs and key risks, with defined review triggers (annual plus event‑based).
- Embed explicit “resilience checks” into major change and investment processes so strategies and tolerances are considered and updated at design gates.
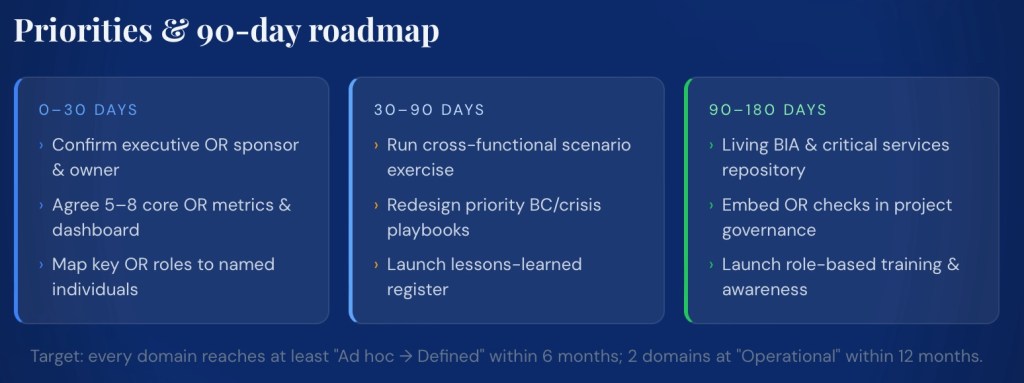
4. Concrete next 90–180 day actions
5. Use for board, client or internal discussions
- Position the assessment as evidence that the organisation has a defined framework but is in the early stages of embedding resilience into operations (overall maturity 28.6%, no domains yet at “Operational Strength”).
- Emphasize that immediate focus is on: clarifying roles and accountability, demonstrating performance through metrics and testing, and simplifying/operationalising response arrangements.
- Show a simple roadmap (90–180 days) with clear milestones and owners rather than a long list of abstract improvements.
- For clients and regulators, highlight strengths in having defined methodologies, policies, and governance structures, while being transparent about the improvement plan for culture, testing, and performance management.